ShardingSphere分库分表组件
ShardingSphere分库分表组件
简介
随着数据量的增长,单个数据库实例的性能瓶颈逐渐显现,导致数据库的查询、插入和更新操作变得越来越慢。为了提高系统的扩展性和可用性,通常采用分库分表技术,将数据分散到多个数据库和表中,减轻单一数据库的压力。
分库分表的主要目的是将数据分散到多个数据库服务器或多个表中,从而提升数据存储能力和访问速度。
分库有两种模式:
- 垂直拆库:电商库 MallDB,业务拆分后就是 UserDB、OrderDB、PayDB…
- 分片拆库:用户库 UserDB,分片库后就是 UserDB_0、UserDB_1、UserDB_xx
分表也有两种模式:
- 垂直拆分:订单表 OrderTable,拆分后就是 OrderTable 以及 OrderExtTable。
- 水平拆分:订单表 OrderTable,拆分后就是 OrderTable_0、 OrderTable_xxx
ShardingSphere介绍
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
目前 ShardingSphere 由 ShardingSphere-JDBC 和 ShardingSphere-Proxy 这 2 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere-JDBC
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
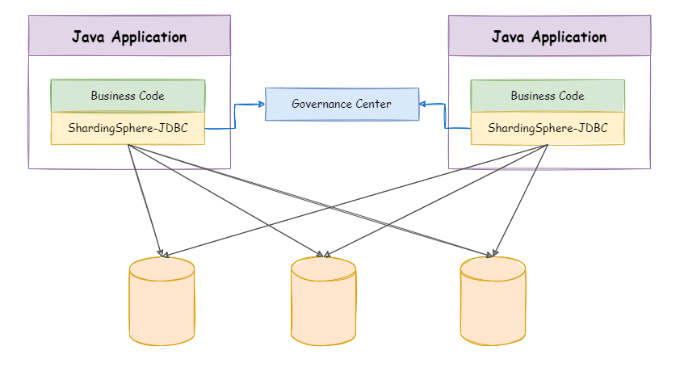
ShardingSphere-Proxy
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
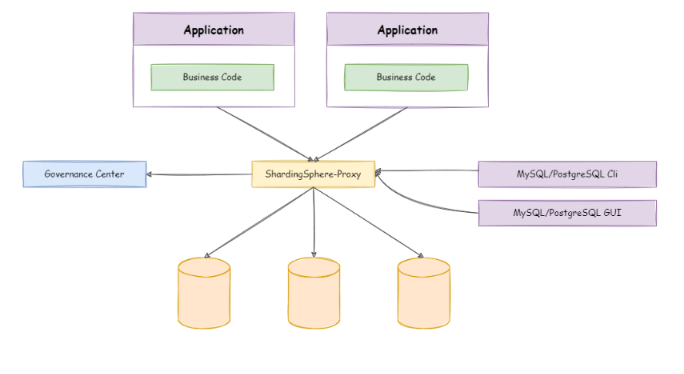
两者对比
总的来看对于Java选手来说 ShardingSphere-JDBC 使用较为简单,它在JDBC层提供服务,理论上无需修改代码,仅需引入 Jar 包并进行配置即可,但是功能相对来说没有那么的强大。
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
ShardingSphere-JDBC
使用方式
ShardingSphere-JDBC 在JDBC层提供服务,所以只支持Java语言使用。
- 引入Maven依赖
1 | <dependency> |
- 创建shardingsphere-config.yaml配置文件(名称随意),详细的配置方式请参照官网
1 | # JDBC 逻辑库名称。在集群模式中,使用该参数来联通 ShardingSphere-JDBC 与 ShardingSphere-Proxy。 |
- 替换application.yaml的数据库配置
1 | # 配置 DataSource Driver |
数据分片
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量。
数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
按照业务拆分的方式称为垂直分片,它的核心理念是专库专用。在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
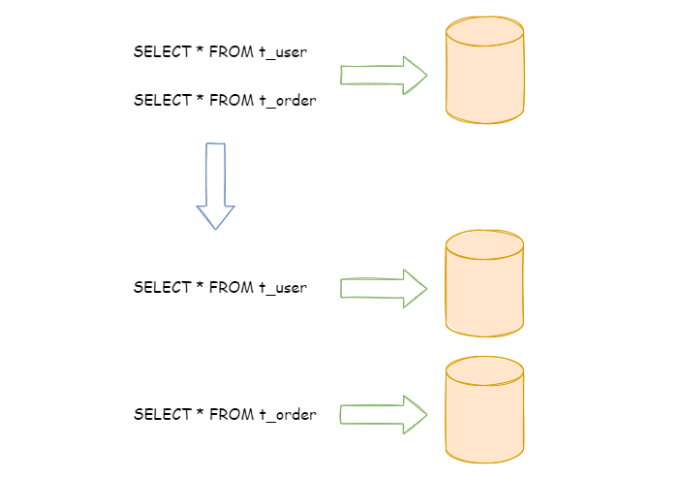
垂直拆分可以缓解数据量和访问量带来的问题,但无法根治,无法真正的解决单点瓶颈。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
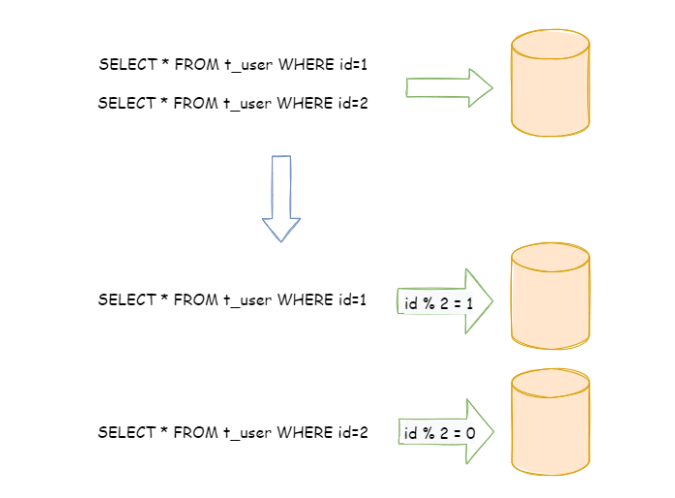
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
带来的挑战
水平分片通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,在进行查询时,需要在查询条件中都包含分片的字段,才能够精准的将查询语句路由到数据分片所在的库,否则会引发全路由(即所有的库都执行)。
运行在单节点数据库中的 SQL,在分片之后的数据库中并不一定能够正确运行。 例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理。
跨库事务也是分布式的数据库集群要面对的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。 在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
核心概念
逻辑表和真实表
逻辑表是相同结构的水平拆分数据库(表)的逻辑名称,如t_user。
真实表是在水平拆分的数据库中真实存在的物理表,如t_user0、t_user1。
绑定表(重要!!!)
指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则
会出现笛卡尔积关联或跨库关联,从而影响查询效率(其实最重要的是可能会得到错误的查询结果,详细请查阅官网)。 例如:t_order表和 t_order_item 表,均按照 order_id分片,并且使用 order_id进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联。
配置方式如下:
1
2
3
4
5
6
7
8
9rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
bindingTables:
- t_order, t_order_item数据节点
数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0,表示ds_0库中的t_order_0表。
分片键
用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,也支持根据多个字段进行分片。
分片算法
用于将数据分片的算法。
行表达式
行表达式是为了解决配置的简化与一体化这两个主要问题。简单来说(排除SPI的TypeName),使用上分两种语法,行表达式中如果出现多个 ${ expression }或 $->{ expression }表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
1
2
3
4
5
6
7${['val1', 'val3']} --> 枚举,会解析为val1和val3
$val{1..3} --> 范围,会解析为val1、val2、val3
${['online', 'offline']}_table${1..3}
最终会解析为以下结果:
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3分布式主键
Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
使用限制
请查阅官网。
YAML配置
官网上参数解释如下:
1 | rules: |
支持的分片算法请查阅官网。
官网上数据分片 YAML 配置示例如下:
1 | dataSources: |
分布式事务
概述
数据库事务需要满足 ACID(原子性、一致性、隔离性、持久性)四个特性。
- 原子性(Atomicity)指事务作为整体来执行,要么全部执行,要么全不执行;
- 一致性(Consistency)指事务应确保数据从一个一致的状态转变为另一个一致的状态;
- 隔离性(Isolation)指多个事务并发执行时,一个事务的执行不应影响其他事务的执行;
- 持久性(Durability)指已提交的事务修改数据会被持久保存。
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。 几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。关系型数据库虽然对本地事务提供了完美的 ACID 原生支持。 但在分布式的场景下,它却成为系统性能的桎梏。 如何让数据库在分布式场景下满足 ACID 的特性或找寻相应的替代方案,是分布式事务的重点工作。
ShardingSphere 对外提供 begin/commit/rollback 传统事务接口,通过 LOCAL,XA,BASE 三种模式提供了分布式事务的能力。
三种模式对比如下:
| LOCAL | XA | BASE | |
|---|---|---|---|
| 业务改造 | 无 | 无 | 需要 Seata Server |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务处理数据不一致的问题 | 短事务 & 低并发 | 长事务 & 高并发 |
对于 LOCAL 事务,在分布式环境下,不保证各个数据库节点之间数据的一致性和隔离性,需要业务方自行处理可能出现的不一致问题。适用于用户希望自行处理分布式环境下数据一致性问题的业务场景。
对于 XA 事务,提供了分布式环境下,对数据强一致性的保证。但是由于存在同步阻塞问题,对性能会有一定影响。适用于对数据一致性要求非常高且对并发性能要求不是很高的业务场景。
对于 BASE 事务,提供了分布式环境下,对数据最终一致性的保证。由于在整个事务过程中,不会像 XA 事务那样全程锁定资源,所以性能较好。适用于对并发性能要求很高并且允许出现短暂数据不一致的业务场景。
LOCAL 事务
LOCAL 模式基于 ShardingSphere 代理的数据库 begin/commit/rolllback 的接口实现, 对于一条逻辑 SQL,ShardingSphere 通过 begin 指令在每个被代理的数据库开启事务,并执行实际 SQL,并执行 commit/rollback。 由于每个数据节点各自管理自己的事务,它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 在性能方面无任何损耗,但在强一致性以及最终一致性方面不能够保证。
XA 事务
XA 事务采用的是 X/OPEN 组织所定义的 DTP 模型 所抽象的 AP(应用程序), TM(事务管理器)和 RM(资源管理器) 概念来保证分布式事务的强一致性。 其中 TM 与 RM 间采用 XA 的协议进行双向通信,通过两阶段提交(2PC)实现。 与传统的本地事务相比,XA 事务增加了准备阶段,数据库除了被动接受提交指令外,还可以反向通知调用方事务是否可以被提交(主流的数据库都支持XA协议,能够作为RM参与到分布式事务中)。 TM 可以收集所有分支事务的准备结果,并于最后进行原子提交,以保证事务的强一致性。
第一阶段:准备阶段(Prepare Phase)
在这个阶段,事务管理器(Transaction Manager,TM)会向所有参与者(Resource Manager,RM)询问是否准备好提交事务。
- 事务管理器发出 “prepare” 请求给所有参与的资源管理器。
- 每个资源管理器执行事务的本地操作,并检查是否能够成功提交。资源管理器会返回以下两种状态之一:
- 准备就绪(Prepared):资源管理器完成了本地操作并准备提交事务。
- 回滚(Rollback):资源管理器由于某些原因无法提交事务(如数据一致性问题或锁冲突等)。
第二阶段:提交或回滚阶段(Commit/Rollback Phase)
根据第一阶段的结果,事务管理器决定是否提交或回滚整个事务:
- 如果所有资源管理器都返回“准备就绪”,事务管理器发出提交请求,所有资源管理器提交事务。
- 如果任何资源管理器返回“回滚”,事务管理器发出回滚请求,所有资源管理器都执行回滚操作。
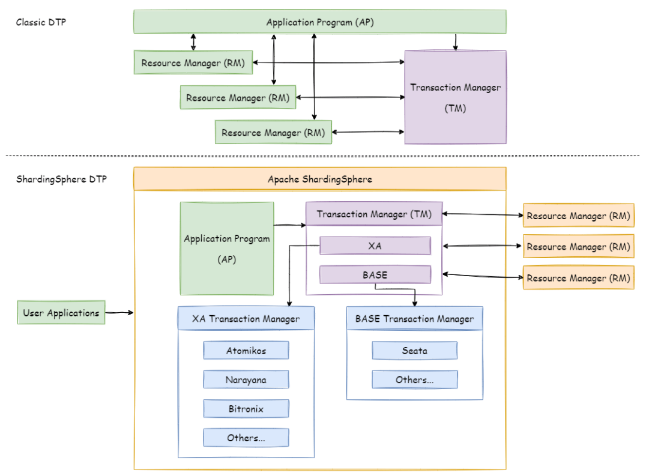
XA 事务建立在 ShardingSphere 代理的数据库 xa start/end/prepare/commit/rollback/recover 的接口上。对于一条逻辑 SQL,ShardingSphere 通过 xa begin 指令在每个被代理的数据库开启事务,内部集成 TM,用于协调各分支事务,并执行 xa commit/rollback。
基于 XA 协议实现的分布式事务,由于在执行的过程中需要对所需资源进行锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将会对并发场景下的性能产生一定的影响。
BASE 事务
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。 BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线;
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉;
- 最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在 ACID 事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。 通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于 ACID 的强一致性事务和基于 BASE 的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 Apache ShardingSphere 集成了 SEATA 作为柔性事务的使用方案。
配置方式
LOCAL
1
2transaction:
defaultType: LOCALXA
1
2
3transaction:
defaultType: XA
providerType: Narayana/Atomikos 还需引入依赖
1
2
3
4
5
6
7
8
9
10
11
12<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-transaction-xa-core</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
<!-- 使用 XA 的 Narayana 模式时,需要引入此模块 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-transaction-xa-narayana</artifactId>
<version>${project.version}</version>
</dependency>BASE
配置和要求过于复杂,请查阅官网。
其他功能
ShardingSphere提供的功能十分强大,本文只介绍了最核心的两个功能,其余请查阅官网。
ShardingSphere-Proxy TODO
如果有机会需要接触到,会更新的。