列式数据库-HBase基础知识
列式数据库-HBase基础知识
HBase简介
HBase介绍
HBase是一个基于HDFS的分布式、面向列的开源数据库,是一个结构化数据的分布式存储系统,是当下比较火的NoSQL数据库之一。HBase使用与Google BigTable非常相识的数据模型。将用户数据存储在带标签的表中,数据行具有可排序的键和任意数量的列,该表存储稀疏,同一表中的行可以具有疯狂变化的列。HBase数据模型的关键在于稀疏、分布式、多维、排序的Key-Value结构。
如何理解稀疏?HBase的表,每行可以有不同的列,即某行该列没有数据,那么这个位置就不占用空间。
HBase逻辑结构
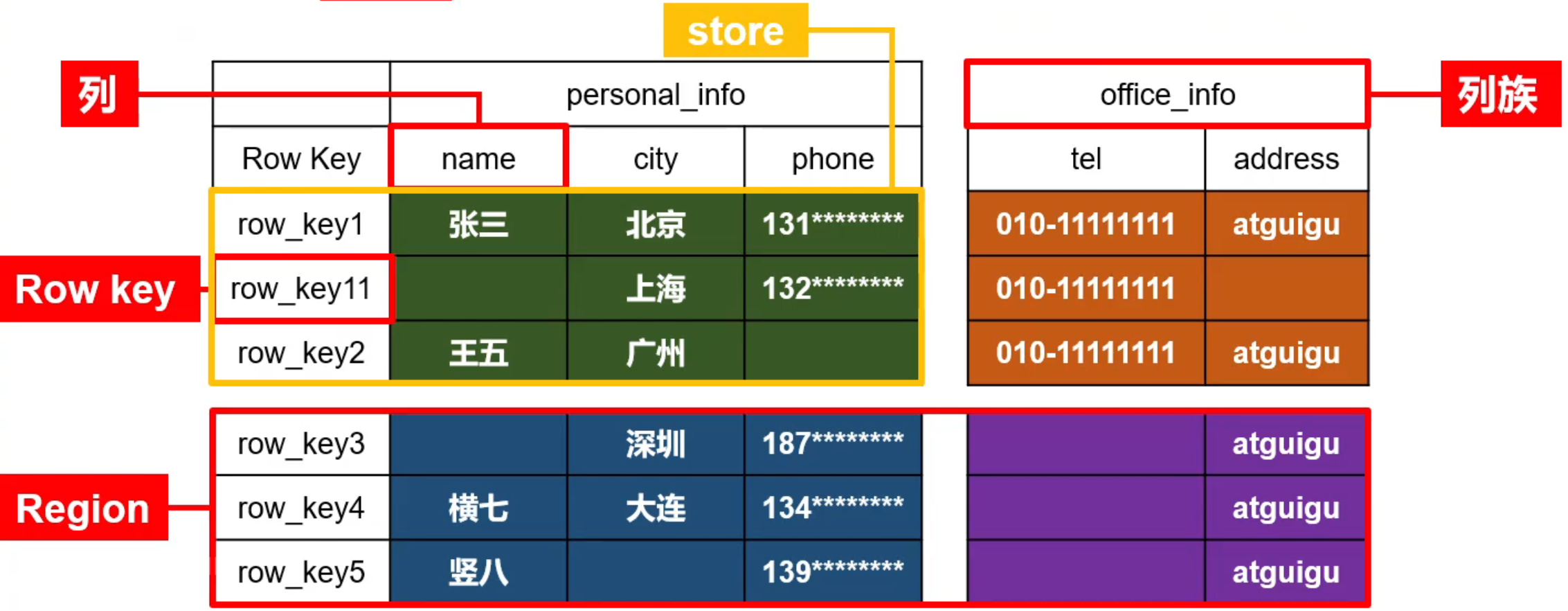
- Row Key:行键,Table的主键,Table中的记录默认按照行键字典序升序排列
- Column Family:列族,Table在水平方向有一个或者多个列族组成,一个列族中可以由任意多个Column组成,一个列族中的Column具有相关性,列族支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换(或者说都是字符串)
- Region:Hbase 表的分片,HBase 表会根据 RowKey值被切分成不同的 region 存储,一个region由[startkey,endkey)表示
- Store:将一个Region按照列族切分为多个Store存储
即数据按照 表 -> Region -> Store组织。
HBase物理结构
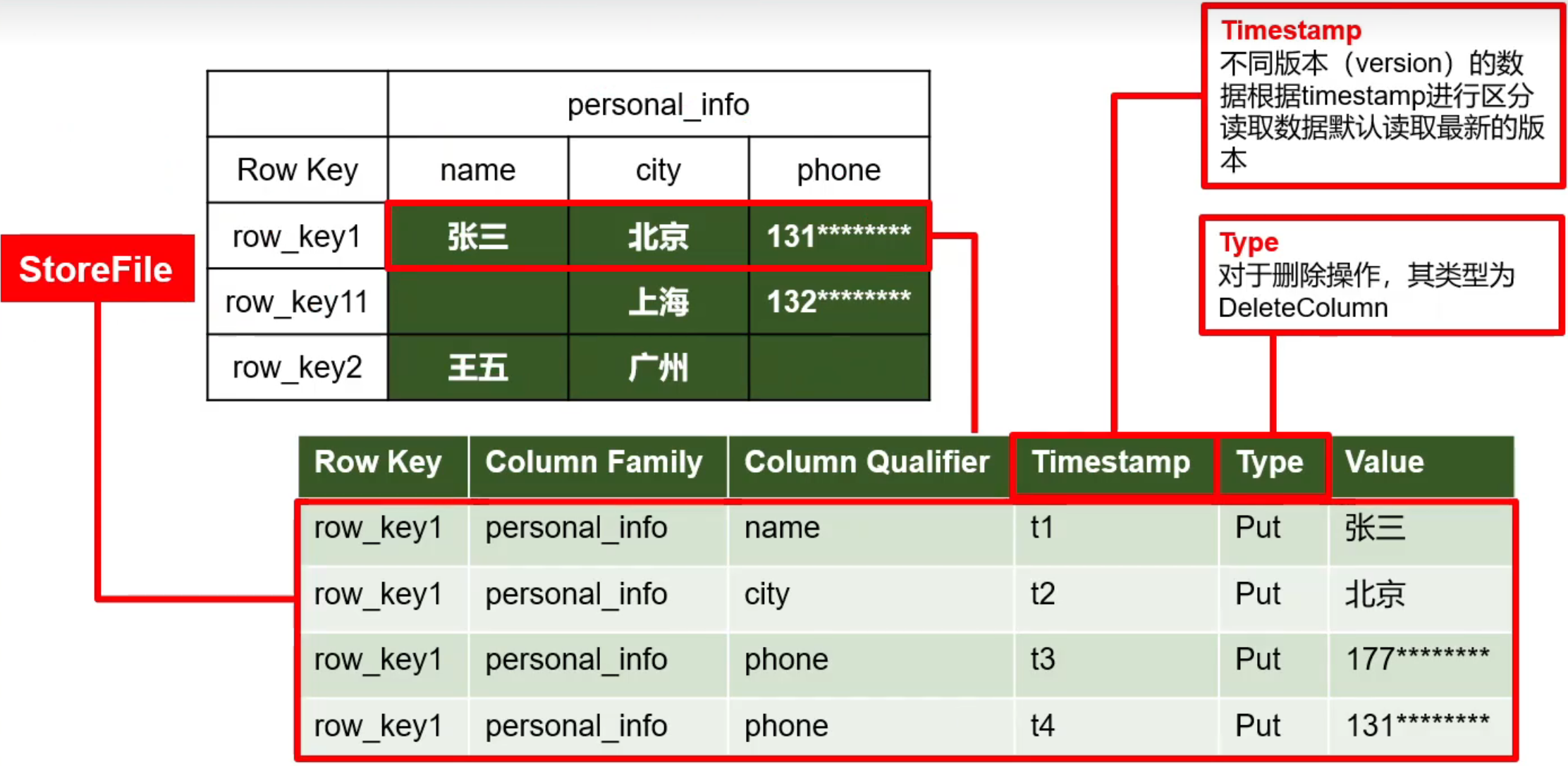
以Store的单位进行存储,存储的物理文件称为StoreFile或HFile。
HBase底层通过HDFS进行数据存储,HDFS本身不支持高效的随机修改,因此HBase进行数据修改时,实际上是追加一条数据(删除也追加),对应的Type是Put,并结合版本号机制实现数据的修改。
当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的
概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile(同Redis的WAL机制) 的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
HBase数据模型
NameSpace
命名空间,类似于关系型数据库database的概念,每个命名空间下有多个表,所有的表都是命名空间的成员,如果没有指定,则在 default 默认的命名空间中。HBase自带两个命名空间,分别是hbase和default,hbase中存放的是HBase内置的表。
Table
表,与关系型数据库不同的是,HBase定义表时,只需要声明列族即可,不需要声明具体的列。同时因为数据存储是稀疏的,往HBase写入数据的时候,字段可以动态、按需指定。HBase能够轻松应对字段变更的场景。
Row
HBase表中的每行数据都由一个RowKey和多个Column组成,数据是按照RowKey的字典序存储的,查询时建议根据RowKey进行检索,否则查询效率极低。
访问HBase中的行,只有以下三种方式:
- 通过单个RowKey访问
- 通过RowKey的range(正则)
- 全表扫描
Column
HBase中的每个列都由 Column Family 列族和 Column Qualifier 列限定符进行限定,例如info:name,列只能在具体的列族下。
TimeStamp
用于标识数据的不同版本(Version),每条数据写入时,HBase会自动为其加上该字段,并写入HBase当前的时间。
每个Cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是64位整型。每个Cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。为了避免数据存在过多版本造成的管理 (包括存贮和索引)负担,HBASE 提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
Cell
由{RowKey, ColumnFamily:ColumnQualifier, TimeStamp}唯一确定的单元,数据按照二进制字字节数组存储(包括RowKey)。
HBase架构
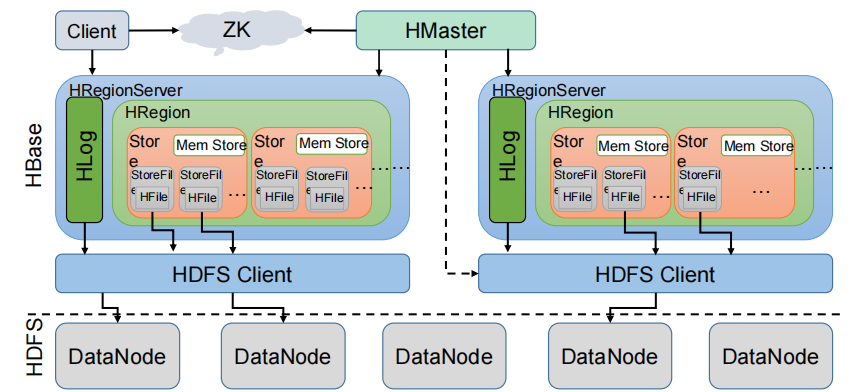
从图中可以看出 Hbase 是由 Client、Zookeeper、Master、RegionServer、HDFS 等几个组件组成,下面来介绍一下几个组件的相关功能:
Client
Client 包含了访问 Hbase 的接口,另外 Client 还维护了对应的 cache 来加速 Hbase 的访问。
Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。
具体工作如下:
通过 Zoopkeeper 来保证集群中只有 1 个 Master 在运行,如果 master 异常,会通过竞争机制产生新的 master 提供服务
通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,通过回调Master的形式通知RegionServer 上下线的信息
通过 Zoopkeeper 存储元数据的统一入口地址
Master
Master 节点的主要职责如下:
为 RegionServer 分配 Region
维护整个集群的负载均衡
维护集群的元数据信息
发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上
当 RegionSever 失效的时候,协调对应 Hlog 的拆分
RegionServer
RegionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
管理 master 为其分配的 Region
处理来自客户端的读写请求
负责和底层 HDFS 的交互,存储数据到 HDFS
负责 Region 变大以后的拆分
负责 Storefile 的合并工作
HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用(Hlog 存储在HDFS)的支持,具体功能概括如下:
- 提供元数据和表数据的底层分布式存储服务
- 数据多副本,保证的高可靠和高可用性
HBase Shell操作(HBase命令)
NameSpace相关
查看所有NameSpace:list_namespace
查看指定NameSpace下的表:list_namespace_tabels ‘namespace名称’
创建NameSpace:create_namespace ‘namespace名称’
查看NameSpace详情:describe_namespace ‘namespace名称’
修改NameSpace:省略,只能修改或删除NameSpace的属性
删除NameSpace:drop_namespace ‘namespace名称’,只能删除空的NameSpace,即内部不包含表
Table相关
DDL
- 查看所有表(不包含HBase内部表):list
- 创建表(命名空间不写默认default空间):
- create ‘命名空间:表名’ ,{NAME=’列族1’, 其他可选属性},{NAME=’列族2’, 其他可选属性}…
- create ‘命名空间:表名’ ,’列族1’,’列族2’…(省略属性写法)
- 查看表信息:describe ‘表名’
- 修改表:alter,可以对列族进行增加或删除,或者修改列族的属性
- 禁用/启用表:enable ‘表名’,disable ‘表名’,表有两种状态,启用或禁用,禁用的表才可以进行修改
- 删除表:drop ‘表名’
- 查看表的region信息:list_regions ‘表名’
DML
- 插入/修改:put ‘表名’,’rowKey’,’列族:列’,’值’
- 查询单条数据:
- get ‘表名’, ‘rowKey’
- get ‘表名’, ‘rowKey’,’列族’
- get ‘表名’, ‘rowKey’,’列族:列’,’列族:列’
- 扫描表的数据:
- scan ‘表名’
- sacn ‘表名’ ,{STARTROW => ‘1’,STOPROW=> ‘10’} ,左开右闭,需要注意是字符串字典序范围,同时还能配合其他属性过滤
- 删除数据
- delete ‘表名’, rowKey’,’列族:列’,删除指定版本数据,默认最新版本,添加Delete标记
- deleteall ‘表名’, rowKey’,’列族:列’,删除所有版本数据,添加DeleteColumn标记,会删除某列的所有版本数据
- deleteall ‘表名’, rowKey’,删除所有版本数据,添加DeleteFamily标记,会删除rowKey所有数据
- 清空表:truncate ‘表名’,会物理删除该表的文件