RabbitMQ基础知识-基于3.x
RabbitMQ基础知识-基于3.x
简介
RabbitMQ 是一款开源的、基于 AMQP(高级消息队列协议)的消息中间件,它最大的特点是通过交换机(Exchange)和绑定(Binding)的机制实现了灵活多变的消息路由策略,同时还具有可靠性高等其他特点。本文将对RabbitMQ 的各个组件依次进行介绍,最后再介绍如何通过Spring AMQP来操作RabbitMQ 。
几种常见MQ的对比如下:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 通过镜像队列、仲裁队列实现 | 主从复制 | 主从复制 | 分区和副本机制 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
RabbitMQ架构图
RabbitMQ的架构图如下,接下来会对每一部分依次进行展开。
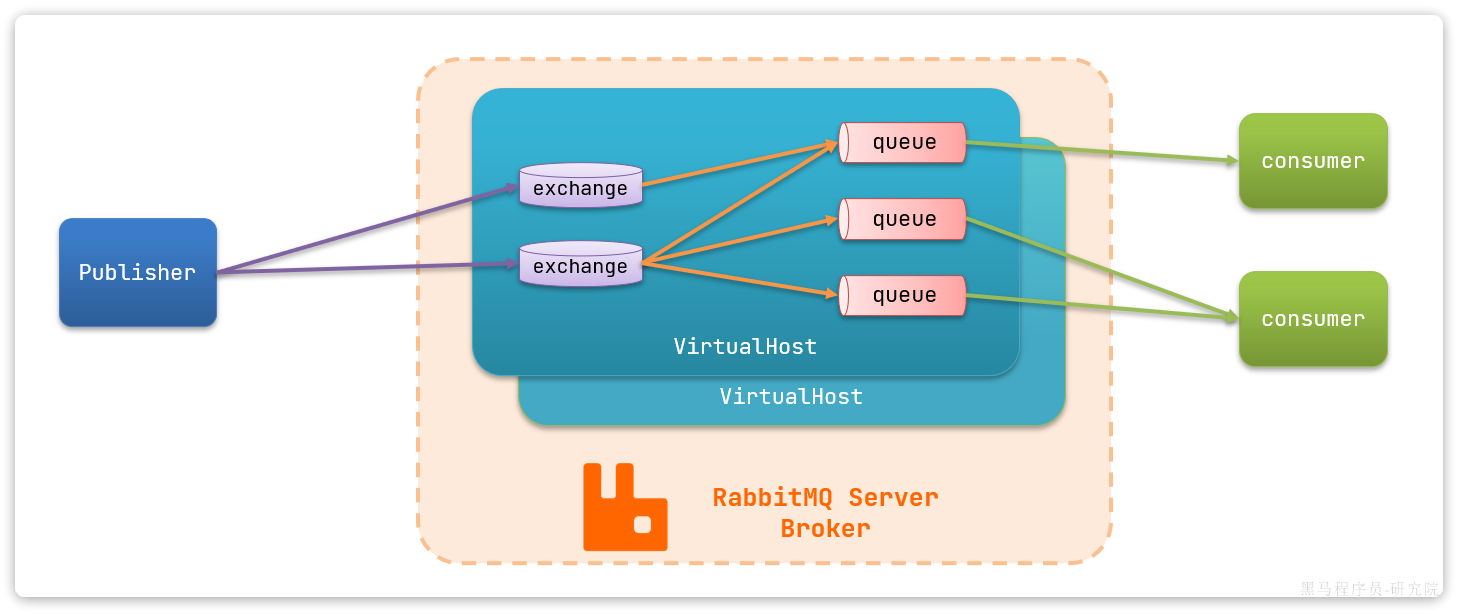
- Publisher:生产者:发送消息的一方。
- Consumer:消费者:消费消息的一方。
- Queue:队列:负责
存储消息。生产者投递的消息会暂存在队列中,等待消费者消费。 - Exchange:交换机:负责
消息路由。生产者发送的消息由交换机决定投递到哪个队列。 - Virtual Host:虚拟主机:起到数据隔离的作用。每个虚拟主机的exchange、queue相互独立。
RabbitMQ消费模型:RabbitMQ没有消费者组的概念,一个Queue里的消息会被所有的消费者共同消费一次(正常情况下),如果需要一条消息能够被消费多次,需要交换机将消息路由到多个队列。
Virtual Host
Virtual Host(虚拟主机)是 RabbitMQ 中的一个逻辑概念,类似于一个独立的消息服务器实例,它为不同的用户、应用程序或业务模块提供了相互隔离的消息环境。不同的虚拟主机之间相互隔离,拥有各自独立的队列、交换机、绑定等资源。
所有的队列、交换机、绑定等资源都属于具体的某个虚拟主机,默认的虚拟主机为/。
应用场景:
- 多租户环境
- 多项目隔离
Exchange
RabbitMQ 中的交换机(Exchange)是消息传递的核心组件,负责接收生产者发送的消息,并根据一定的规则将消息路由到一个或多个队列中,接下来将对常用的几种交换机类型进行介绍。
交换机不具备存储消息的能力,如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失。
广播交换机Fanout
Fanout交换机会将消息路由到与它绑定的每个队列中。
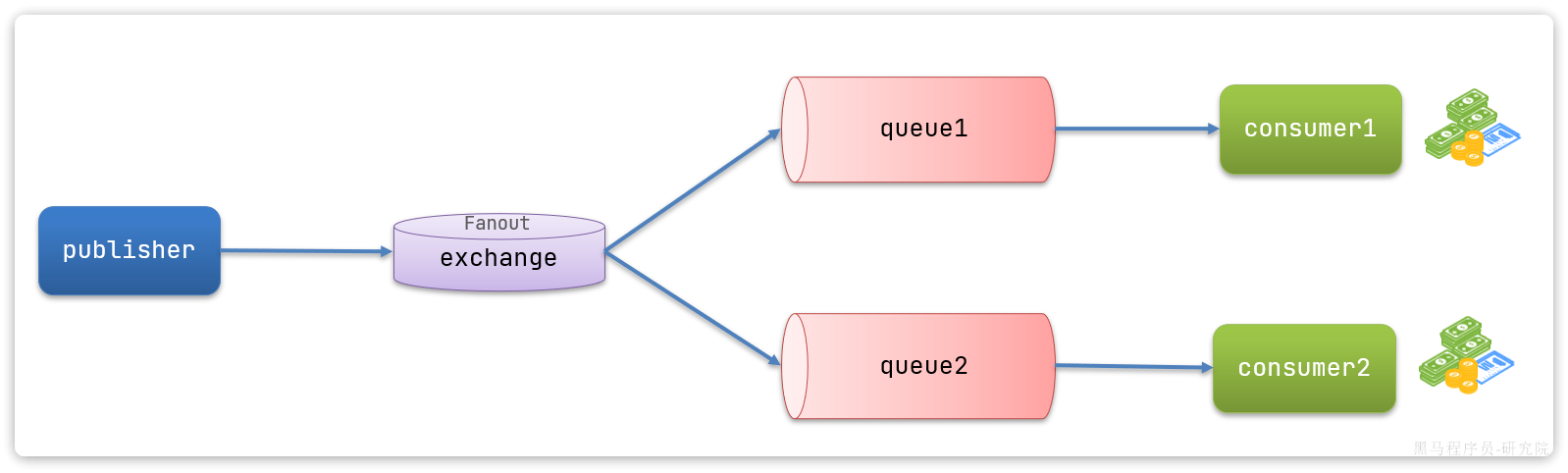
消息的发送方发送的所有消息都会被路由到与Fanout交换机绑定的queue1和queue2中。
定向交换机Direct
对于Direct交换机来说,队列与它进行绑定时需要指定一个或多个路由键RoutingKey,消息的发送方在给Direct交换机发送消息时,需要指定消息的路由键(防止混淆我简称为消息键),Direct交换机会根据消息键进行判断,将消息路由到与交换机绑定的路由键与消息键相同的队列中。
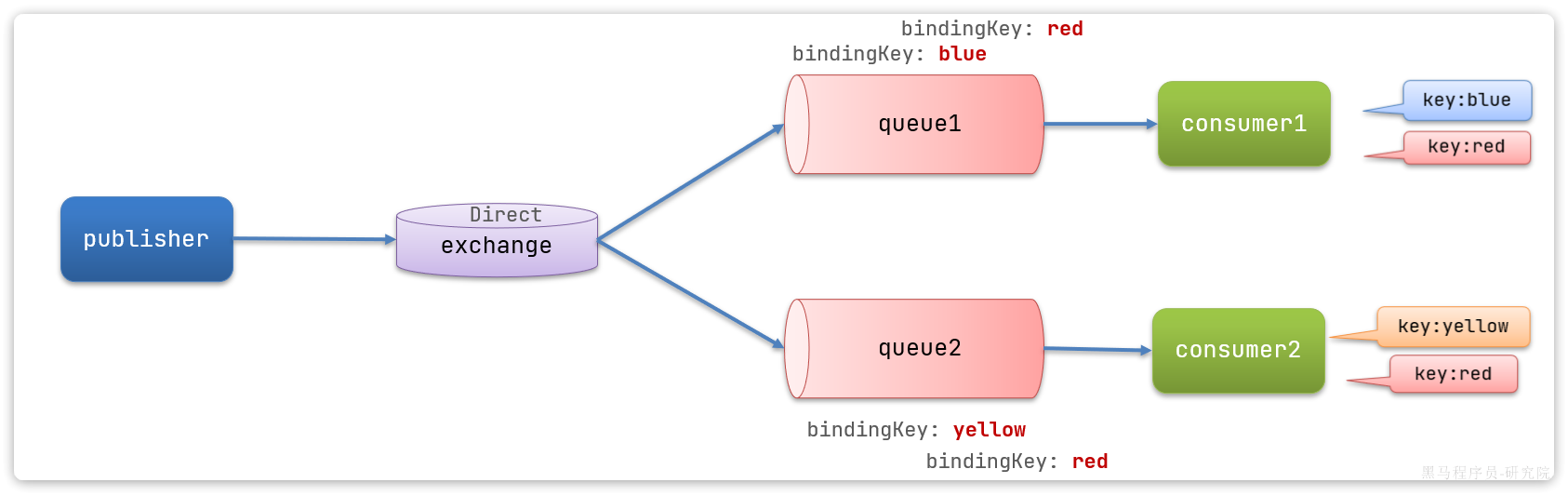
消息的发送方发送一条消息键为blue的消息,该消息会被Direct交换机路由到queue1中;消息的发送方发送一条消息键为red的消息,该消息会被Direct交换机路由到queue1和queue2中。
主题交换机Topic
Topic交换机与Direct类似,都是根据消息键进行匹配,然后路由到匹配的队列中,区别在于队列与Topic交换机进行绑定时,可以使用通配符进行绑定。
通配符规则(消息键的单词之间使用.分割 ):
- #:匹配0个或多个词
- *:匹配恰好1个词
假设队列queue1与交换机绑定的路由键是jujuyi.*,那么消息键为jujuyi.cn的消息能够被路由到queue1中,消息键为jujuyi的消息不能被路由到queue1中。
Queue
默认的队列为经典队列Classic。
队列中会存储用户的消息,需要注意的是,RabbitMQ的队列、交换机以及用户的消息都可以为临时的,重启或者RabbitMQ崩溃后队列就会消失,队列与交换机在创建时可以指定是否为持久的,同时发送消息时也可以指定是持久的或者临时的。在Spring SMQP中创建的队列与交换机以及发送的消息默认都是持久的(不保证每个版本都如此)。在发送消息时,如果想指定为临时消息,需设置消息的DeliveryMode。
临时消息会保存在内存中,若内存空间不足,会将消息保存到磁盘,称之为PageOut,此时RabbitMQ会阻塞队列进程,因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。对于持久消息,RabbitMQ也会将一些消息放入内存中以降低消息收发的延迟(即放入内存中也存入了磁盘),当消息过多时,虽然不会直接阻塞,但是对性能会有些许影响。
为了解决这些问题,RabbitMQ的3.6版本开始,就增加了惰性队列Lazy Queues的模式,在3.12版本之后,LazyQueue已经成为所有队列的默认格式。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
- 支持数百万条的消息存储
优先级队列
在创建队列的时候可以指定参数x-max-priority,值的范围是1到255,推荐在1-5之间。设置参数x-max-priority参数为非0即开启优先级队列功能,此时用户发送消息时可指定消息优先级(需小于设置的x-max-priority),数字越大优先级越高,优先级高的会被先消费。
1 | rabbitTemplate.convertAndSend("priority.direct", "test", "hello", message->{ |
优先级队列也属于经典队列Classic,Classic默认是不开启消息优先级的
Publisher
生产者主要涉及到消息发送的可靠性,即消息能够正确的发送到队列中。
生产者重试机制
生产者发送消息时,可能出现了网络故障,导致与MQ的连接中断,此时生产者可以进行发送消息的重试,SpringAMQP提供了消息发送时的重试机制。相关配置如下:
1 | spring: |
需要注意的是,当网络不稳定而进行消息发送的重试时,执行发送消息的线程会同步阻塞。
生产者确认机制
RabbitMQ 的生产者确认机制是一种确保消息成功发送到消息中间件的机制,包括Publisher Confirm和Publisher Return两种。在开启生产者确认机制的情况下,当生产者发送消息给RabbitMQ 后,RabbitMQ 会根据消息处理的情况返回对应的信息,默认Publisher Confirm和Publisher Return都是关闭状态,需要配置进行开启。
1 | spring: |
Publisher Confirm
当生产者向 RabbitMQ 发送消息后,RabbitMQ 会返回一个确认信号给生产者,告知消息是否已被成功接收和处理。如果消息成功被接收并处理,生产者会收到一个确认通知(ack);如果消息发送失败或处理过程中出现问题,生产者会收到一个否定确认通知(nack)。
配置文件中的publisher-confirm-type有以下三种可选:
- none:关闭confirm机制
- simple:同步阻塞等待MQ的回执
- correlated:MQ异步回调返回回执
消息被成功接收和处理即会响应ack,消息被成功接收和处理的含义是:
- 消息根据交换机与队列的绑定关系需要路由到队列:当成功路由到队列后会返回ack(如果是持久化队列需要队列持久化消息后返回)
- 消息根据交换机与队列的绑定关系需要无需路由到队列:直接返回ack
其余情况均为nack,比如交换机名字错误、网络故障等
使用方式:
1 | //旧版本 |
新版本的使用方式可能跟你在其他地方看到的不一样,严格上这并不算新版的Publisher Confirm机制的使用方式,由于新版本不再支持针对每条消息单独设置Callback,而是只能设置一个全局唯一的Callback,个人认为局限性太大,使用上述方式就十分灵活,可以根据需要选择同步和异步并且不同业务可以有不同的处理方式。
在此还是贴一下新版使用Publisher Confirm机制的标准代码:
1 |
|
需要注意的是,只能配置一个。
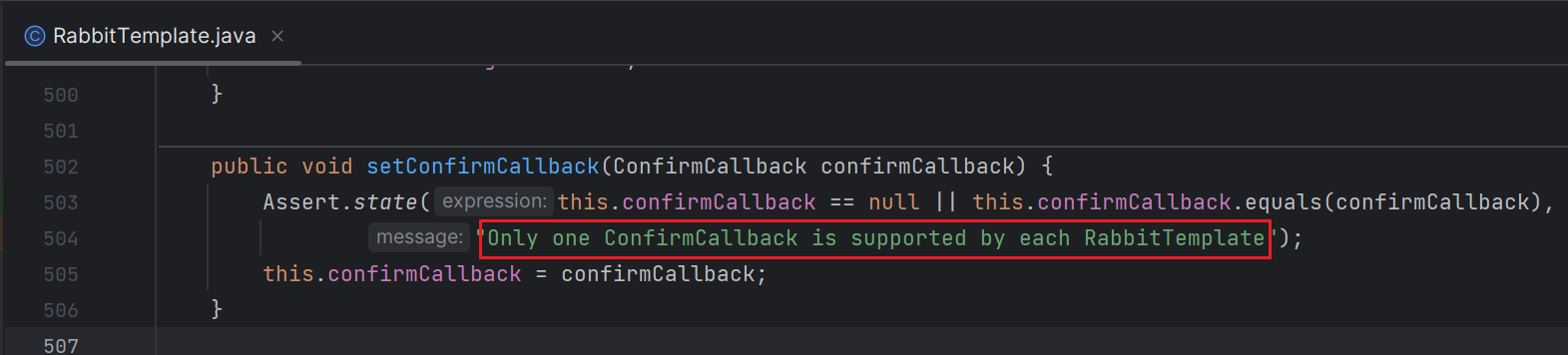
Publisher Return
Publisher Return 是一种机制,用于当消息无法被正确路由到队列时,将消息返回给生产者。一般来说不建议开启,因为消息路由到队列失败的原因往往是由于开发者的错误导致。如RoutingKey错误、交换机名字错误等。
使用方式(也是只能配置一个):
1 |
|
消息唯一ID
给消息一个唯一ID有助于保障业务幂等性,防止消息被重复消费。SpringAMQP中用户发送的消息都会经过MessageConverter进行转换(序列化),一般使用的是JSON序列化,该序列化器自带了MessageID的功能,配置方式如下:
1 |
|
由交换机路由到多个队列的同一条Message的ID是一样的,但是Message本身还有一个deliveryTag标识,是RabbitMQ自动生成的,它是全局唯一的,由交换机路由到多个队列的同一条Message的deliveryTag是不同的,在消费者进行手动Ack时需要给出deliveryTag。
延迟消息
延迟消息是一种消息传递机制,它允许消息生产者发送消息后,消息在消息中间件中被暂存一段时间,然后在预先设定的延迟时间到达后,才会被投递到消费者进行处理。一个大家都接触过的场景是订单超时自动取消。
在RabbitMQ中,实现延迟消息的常用方式有以下两种:
- 死信交换机+TTL
- 延迟消息插件
死信交换机+TTL
首先介绍什么是死信,死信指的是无法被正常消费的消息,当一个队列中的消息满足下列情况之一时,可以称为死信(dead letter):
- 消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息满了,无法投递,根据队列先进先出的原则,此时最早的消息会成为死信
当消息成为所在队列的死信时,并且这个队列通过dead-letter-exchange属性指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机就称为死信交换机(Dead Letter Exchange),如果未指定死信交换机,消息会被丢弃。
通过死信交换机+消息TTL的机制,即可实现延迟消息的功能:queue1中的消息没有消费者进行消费,消息达到设置的TTL超时后被死信交换机路由到queue2,再由消费者进行消费,需要注意的时,无论是之前的交换机还是死信交换机,都是通过最初的消息键路由到队列的。
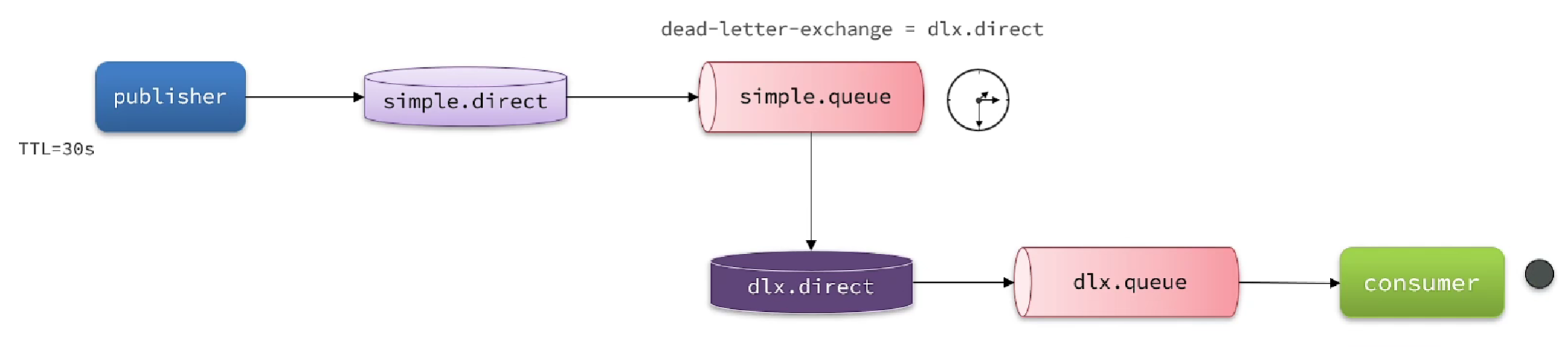
发送消息时通过MessagePostProcessor设置消息的TTL。
1 | rabbitTemplate.convertAndSend("demo.direct", |
延迟消息插件
RabbitMQ社区提供了一个延迟消息插件来实现延迟消息的效果,地址:GitHub - Delayed Messaging for RabbitMQ。该插件可让消息在交换机中暂存,到达预定的时间后再路由到队列。
延迟消息插件内部会维护一个本地数据库表,同时使用Elang Timers功能实现计时。如果消息的延迟时间设置较长,可能会导致堆积的延迟消息非常多,会带来较大的CPU开销,同时延迟消息的时间会存在误差。因此,不建议设置延迟时间过长的延迟消息。
需要在创建交换机时指定为延迟交换机。
1 |
|
同样通过MessagePostProcessor设置消息的延迟时间。
1 | rabbitTemplate.convertAndSend("delay.direct", |
延迟消息插件对Publisher Confirm的影响TODO
事务消息
RabbitMQ也是支持事务的,RabbitMQ的事务能够支持生产者发送多条消息的原子性,并且Spring AMQP也将其接入了@Transactional注解中,当配置了rabbitTemplate.setChannelTransacted(true)并向容器注入了RabbitTransactionManager时,会开启对事务的支持。
感兴趣可以自行详细了解,感觉用的不多。
Consumer
当消息由RabbitMQ到达消费者以后,RabbitMQ需要知道消费者对消息的处理状态,因为消息投递给消费者并不代表就一定被正确消费了,有可能消费者发生了故障。RabbitMQ提供了消费者确认机制(Consumer Acknowledgement),当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态,可选值如下:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
消费者确认机制
由于消息回执的处理代码比较统一(类似于事务,使用try-catch,成功ack,异常nack或reject),因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
- none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中调用api,发送
ack或reject,存在业务入侵,但更灵活 - auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:
- 如果是
业务异常,会自动返回nack - 如果是
消息处理或校验异常,自动返回reject
- 如果是
配置方式如下:
1 | spring: |
失败重试机制
当消息消费失败,会返回nack,消息会不断requeue(重入队)到队列,该消息会再次被投递给消费者进行消费,极端情况就是消费者一直无法执行成功,为了应对上述情况Spring AMQP又提供了消费者失败重试机制:在消费者出现异常时利用本地重试,而不是无限制的requeue到队列,当开启重试机制且重试达到最大次数后,Spring会根据MessageRecoverer进行处理。
默认的MessageRecoverer的实现是RejectAndDontRequeueRecoverer,此时会返回reject,消息会被丢弃。还有以下其他几种,可根据需要进行配置:
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机(死信)
配置方式如下:
1 | spring: |
1 |
|
Spring AMQP
Spring AMQP项目将Spring核心概念应用于基于AMQP协议的消息传递解决方案的开发。它提供了一个模板Template作为发送和接收消息的高级抽象。它还通过“侦听器容器”为消息驱动的pojo提供支持。Spring AMQP由两部分组成;spring-amqp是基本抽象,spring-rabbit是RabbitMQ的实现(目前基于AMQP协议最主流的MQ)。
接下来将介绍如何通过Spring AMQP操作RabbitMQ。
pom
1 | <dependency> |
application.yaml
1 | spring: |
序列化器
1 |
|
发送消息
1 | public class SpringAMQPTest { |
接收消息
1 |
|
集群
RabbitMQ集群的交换器(Exchange)和绑定(Binding)信息会在集群中的所有节点间进行复制,RabbitMQ集群队列消息的复制可以通过镜像队列(基于Classic队列)和仲裁队列两种方式实现,简单来说镜像队列采用的是主从架构,仲裁队列采用的是副本机制,镜像队列的形式不做过多介绍,在实际的使用中肯定是优先使用仲裁队列,因为在最新的RabbitMQ4.x中镜像队列已经被移除了。
仲裁队列
仲裁队列是基于 Raft 共识算法的一种队列类型。它通过维护多个副本来确保消息的一致性和可用性。当生产者发送消息时,消息会被复制到仲裁队列的多个副本节点中。在进行消息的写入、读取等操作时,需要多数(Quorum)节点达成一致才能完成操作。
相较于镜像队列的好处是提供了高可靠性和强一致性,坏处是性能会有所下降。
以下是仲裁队列和经典队列Classic的对比(来源于官网)。
| Feature | Classic queues | Quorum queues |
|---|---|---|
| Non-durable queues | yes | no |
| Message replication | no | yes |
| Exclusivity | yes | no |
| Per message persistence | per message | always |
| Membership changes | no | semi-automatic |
| Message TTL (Time-To-Live) | yes | yes |
| Queue TTL | yes | partially (lease is not renewed on queue re-declaration) |
| Queue length limits | yes | yes (except x-overflow: reject-publish-dlx) |
| Keeps messages in memory | see Classic Queues | never (see Resource Use) |
| Message priority | yes | yes |
| Single Active Consumer | yes | yes |
| Consumer exclusivity | yes | no (use Single Active Consumer) |
| Consumer priority | yes | yes |
| Dead letter exchanges | yes | yes |
| Adheres to policies | yes | yes (see Policy support) |
| Poison message handling | no | yes |
| Global QoS Prefetch | yes | no |
| Server-named queues | yes | no |