布隆过滤器讲解
布隆过滤器讲解
简介
布隆过滤器(Bloom Filter)是1970年由布隆提出的一种空间效率极高的概率型数据结构。它实际上是一个很长的二进制向量和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是高效空间利用率和快速查询,缺点是有一定的误识别率和删除困难,接下来我将基于我对布隆过滤器的思考对布隆过滤器进行详细的讲解(试着带你思考一下)。
怎么检索一个元素是否在一个集合中?
在Java语言当中,想快速的检索一个元素是否在一个集合中,想必大家的回答几乎都是说通过Set来实现,那么Set有什么特点呢?
Set的最常用的实现类是HashSet,基于哈希表进行时间效率的优化,首先根据元素的hashCode计算哈希值,通过哈希值对应到哈希数组中的哈希槽(通俗来说就是数组中的下标),这相当于进行了分流,只需再比对相同哈希槽内是否存在相同的元素即可实现快速的判断元素是否在一个集合中。
那么布隆过滤器的作用也是用于检索一个元素是否在一个集合中,为什么不使用HashSet而是使用布隆过滤器的呢?
其实HashSet与布隆过滤器的实现方式不同,各有利弊。
HashSet中元素的存储,是真的会把元素存储在哈希槽所对应的链表或者红黑树中,这样带来的好处是元素在不在集合中的判断是100%准确的,当有多个元素对应的哈希槽相同时,其实这称之为发生了哈希冲突,此时会依次遍历集合中相同哈希槽的元素,来进行判断元素是否在集合中,因为HashSet将集合中的元素真正的进行了存储,所以元素在不在集合中的判断是100%准确的。
那么坏处其实是内存占用过高,当有海量数据时,想通过HashSet来进行判断,那么这些数据都需要在内存中,显然是不现实的。
那么,接下来我将向你介绍一下布隆过滤器是如何实现的。
布隆过滤器
布隆过滤器适用于海量数据场景,那么这也意味着,它并不会将存放进集合的元素真正的进行存储,这也是布隆过滤器会产生误判的原因。
我们来想象一下,既然允许误判,那在HashSet中发生哈希冲突的时候,就直接认为该元素在集合中不就好了,这样只需标记某个哈希槽是否存在元素就好,也不需要将元素真正的进行存储,那么就能够支持海量数据的场景了。
事实上,上面这种实现方式,就是最简单的布隆过滤器。布隆过滤器通过二进制向量来存储某个哈希槽是否存在元素(这里采用了状态压缩对空间占用进行进一步的优化),并通过一系列随机映射函数来计算元素对应的哈希槽。
布隆过滤器的示意图如下:
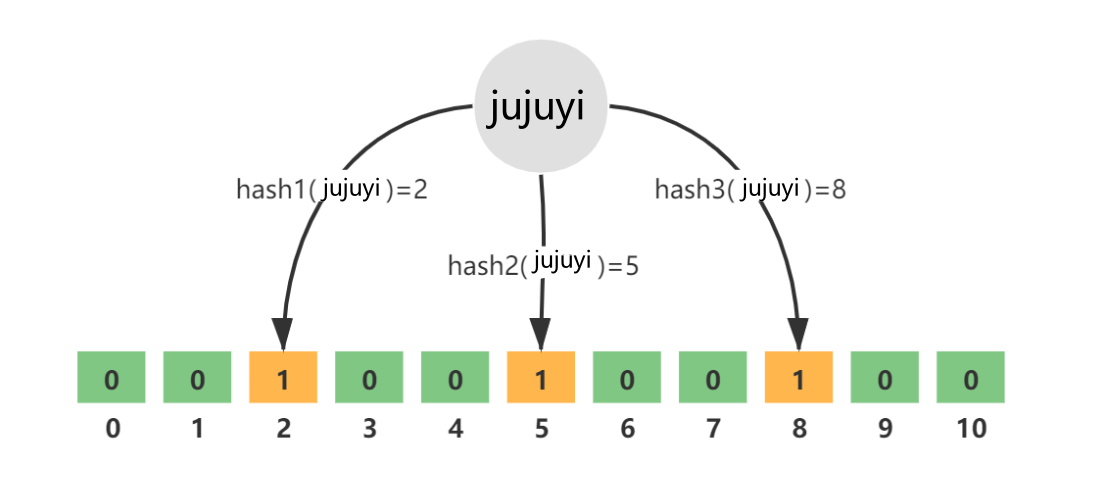
在上面的示意图中,通过三个随机映射函数将jujuyi映射到了三个位置,将jujuyi加入布隆过滤器后,这三处的位置的值将赋为1,在查询元素时,若所有随机映射函数所计算的位置都为1,则判断该元素为在集合中,反之判断为不在集合中。因为会有冲突的概率,所以会产生误判。
布隆过滤器的误判
由于在加入元素时,所有随机映射函数所计算的位置都将赋为1,所以加入的元素一定是能够判断在集合中的。某些不在集合中的元素,有可能因为冲突的产生,所计算的位置和其他已加入布隆过滤器的元素的位置相同,从而造成误判。如果布隆过滤器判断元素不在集合中,那么该元素是一定不在集合中的(因为所有随机映射函数所计算的位置都将赋为1)。
总结为:布隆过滤器能够判断某个元素可能存在集合中或者一定不存在集合中,布隆过滤器的误判只有一种情况,即将不存在集合中的元素误判为存在。
布隆过滤器的删除困难
加入到集合中的元素所计算的位置是会有冲突的,如果删除某个元素时将该该元素所计算的位置都赋为0,肯定是不行的,这有可能会造成将存在集合中的元素误判为不存在。
即使采用记数布隆过滤器(不使用0,1标识某个槽是否有元素,而是记录该槽的元素个数),也没法做到准确的删除。
影响布隆过滤器的因素
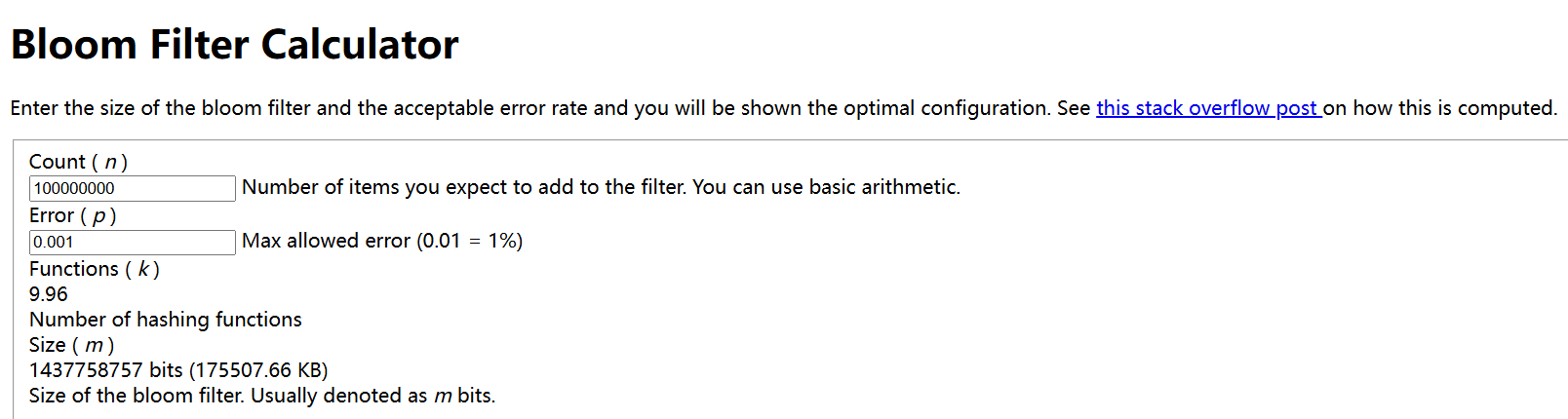
从布隆过滤器的实现方式看,不难看出,当能够用来记录的二进制向量越长或者随机映射函数越多,布隆过滤器的冲突概率越低,这个网站能够计算布隆过滤器中期望放入的元素数量和期望的错误率所需的二进制向量占用空间和随机映射函数数量。
布隆过滤器的实现
在Redisson(基于Redis实现的驻内存数据网格)中提供了布隆过滤器的实现RBloomFilter,以下是简单示例。
声明:
1 |
|
使用:
1 | //加入元素 |